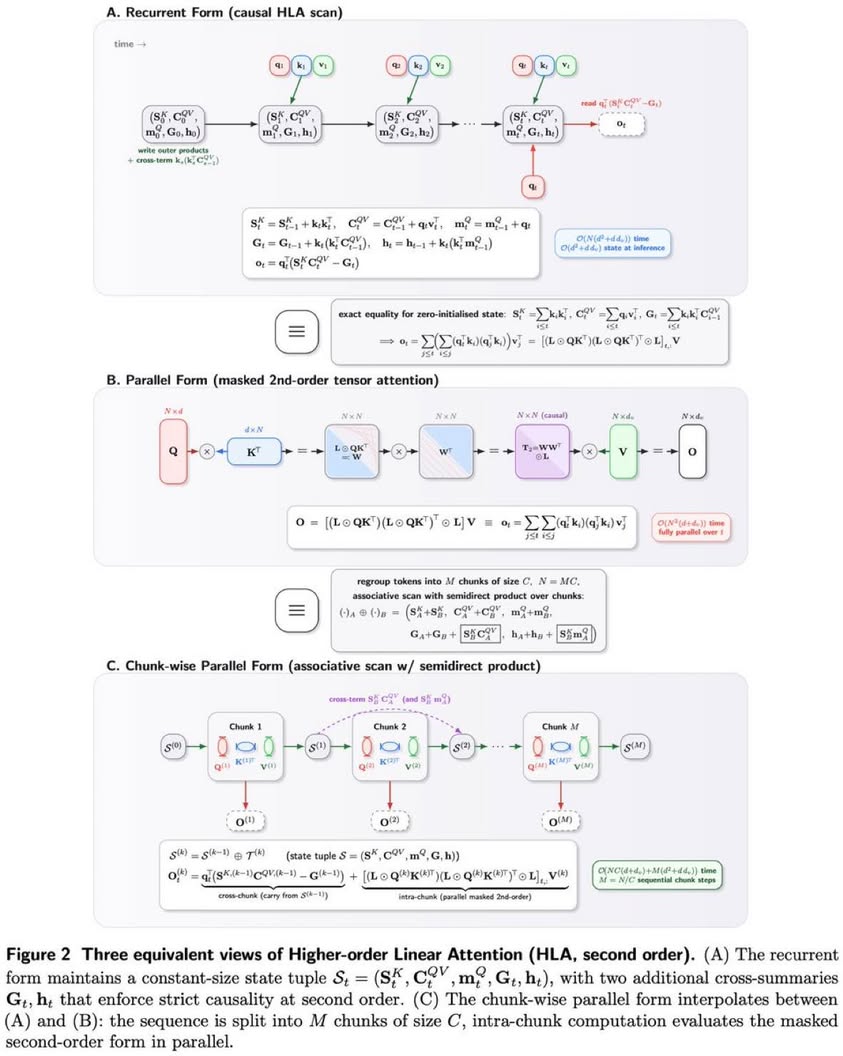
Wait what if Linear Attention was secretly hiding higher-order powers all along? 😐 Princeton AI broke the linear attent...
Wait what if Linear Attention was secretly hiding higher-order powers all along? 😐 Princeton AI broke the linear attention ceiling. Higher-Order Linear Attention (HLA) = RNNs/SSMs in disguise. Same constant-size state, Linear time, But now with higher-order token interactions. generalized state-space duality. - Higher-order interactions - Still linear time & constant state - Fully causal & parallelizable This is huge for efficient transformers & streaming models. Causal & parallel training in one model. This might be the next leap toward efficient long-context & streaming intelligence. Repo : -/github.com/yifanzhang-pro/HLA