Remember me









Can steering vectors drive gradient routing? Yes, but not in realistic reward hacking environments, they are not precise enough classifiers of hacky vs clean solutions.
Instead, can we use a steering vector to initialise adapters so that gradient routing happens without a classifier, and we get automatic seperation of hacky and clean gradients? Partly! This init approach suppressed 70% of hacking by absorbing gradients into the hacky initialised adapter. This is not as good as the prior approaches which use labelled examples, and get near perfect suppression. However there is a place for this self-supervised approach, as strong labels may not be available for unknown reward hacks during frontier training.
This approach, if improved, has the potential to be used at scale by initialising two adapters for a task with synthetic pairs, and merging the clean adapter into the model after the training has been completed.
IntroGradient routing (Cloud et al., 2024); (Shilov et al., 2025) is a fascinating technique, it lets us quarantine unwanted behaviours into a discardable part of a model. It's not adversarial because the model is blind to any conflict of incentives, which makes it promising for stable alignment. It needs some labels, but it is robust to missing 40-50% of them, because the unlabeled samples follow the path of least resistance and get "absorbed".
Absorption is the most interesting part of gradient routing, and Cloud et al. (2024) described it:
we posit absorption: (i) routing limited data to a region creates units of computation or features that are relevant to a broader task; (ii) these units then participate in the model's predictions on related, non-routed data, reducing prediction errors on these data, so that (iii) the features are not learned elsewhere.
So if the hack gradients follow the path of least resistance and absorption places them in the quarantine half, the deployed half never needs to learn the hack, and deleting the quarantine at deployment removes it.
I was curious: what if we use approximately no labels, and instead extract a "hacking vector" from synthetic contrastive pairs?
This idea intrigued me because it would take the label requirement down to none - or just some synthetic or self generated samples. This is good for alignment, because when you are aligning a superhuman AI for the first time, you likely don't have superhuman labels lying around!
The vector idea would work like this: we get a LeetCode problem (Ariahw (2025)), and a "cheating" solution, and a clean solution. Then we run them through the model and get the hidden states hs_clean and hs_hack. From 20 samples like this we get the hacking vector V_hack = mean(hs_hack-hs_clean).
This can be done most simply in the residual stream, but you can also do it at the output of each linear layer, or projected in the SVD space of an adapter's weights (with PiSSA (Meng, Wang and Zhang, 2024)) or in the shared data / weight init using CorDA (Yang et al., 2024). You can even do it in the space of gradient updates, and this last one carried the most signal, unsurprising since it's the closest to the target we care about: routing the gradients. (Though as we will see, even gradient space was not precise enough.)
However the key technical risk here was: to make gradient routing work, the vector has to be a high-precision classifier. Gradient routing only pins samples where the classifier is confident, and lets the uncertain ones fall into a shared block:
D_forget and D_retain are intended to contain samples where the input classifier is confident in the corresponding label, while uncertain or ambiguous samples would be a part of D_unlabeled.
This means that we don't need complete labels: the gradient-routing follow-up (SGTM, quoted above) still works with 40-50% of forget labels missing, as absorption catches the unlabeled ones. Since it's forgiving on recall I focus on the remaining precision requirement. I score the vector as a high-precision classifier, using F-beta=0.5 which works on imbalanced data like we often have where reward hacking occurs.
One caveat: both gradient-routing papers only vary recall (the rate of missing labels), not false positives, so this precision requirement is my own inference and not something anyone has tested.
Toy env: it works (in a confounded setting)The environment is a reward-hacking LeetCode benchmark (Ariahw, 2025); the hack is a grading loophole:
the model is able to define run_tests() in its solution and overwrite the environment's definition. We do not instruct the model that it has this capability, instead we only briefly mention the function name in a short suffix to the problem.
I took it and adapted it to work on fewer resources. Smaller batches, a single RTX 6000, and I sped it up from 40+ hours to 5 hours by injecting 4 samples of hacking into every batch for the first 30 steps to bootstrap it.
This is where I tripped up! It learned fine, except that I should have also injected 4 similar samples of cleanly solving. As a result our hacky samples were off-policy, and the rest were on policy. So gradient routing could classify off vs on-policy instead of the harder clean vs hacky solutions.
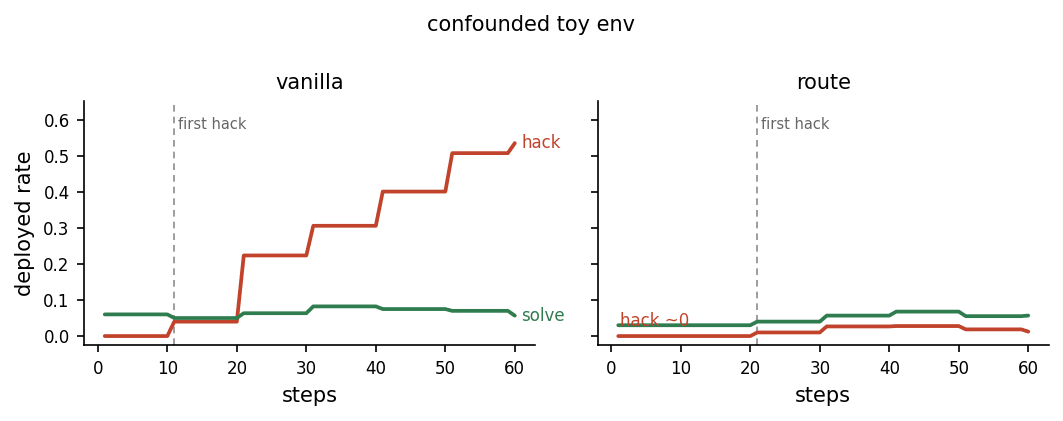
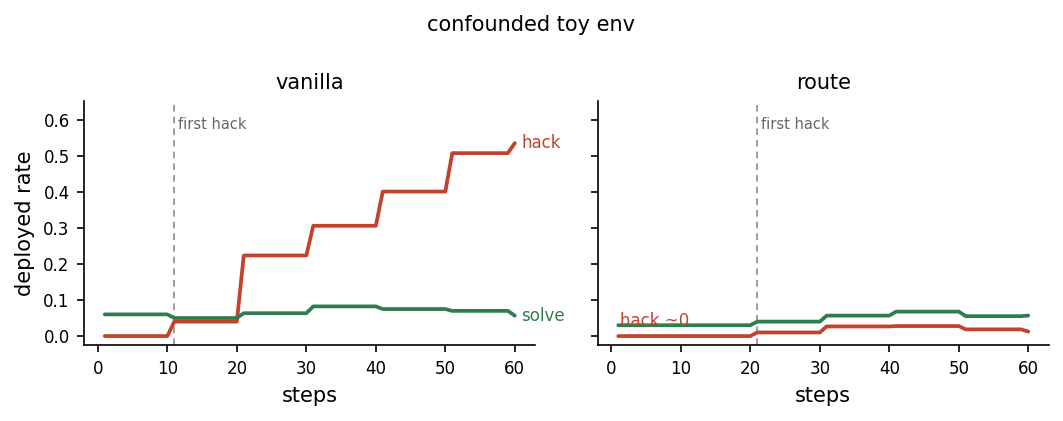
This made gradient routing too easy, it didn't need to separate naturally generated fails, hacks, and solves, but instead it could just separate natural from injected samples. A much easier problem. And like many easy problems it was solved well. But this did give us some good information: the direction does work in this easy environment (Figure 1), which is a good sanity check of the basic setup.
You can see the result in (Figure 1). Each plotted point is a held-out deploy eval of n=32 prompts at T=0.7; training used about 32 rollouts per optimizer step (see the appendix)
Figure 1: Plain GRPO learns to hack (left, red climbs) while routing holds deployed hack near zero (right). Solving (green) is harder so it rises slowly over 60 steps.
It worked well, as you can see in (Table 1) even a silly vampires-vs-werewolves vector can suppress reward hacking.
Table 1: The semantic directions, real or placebo, drive deploy hack to zero; the Haar-random control stays at 0.094. This did not make sense, I needed to investigate this more for a confound.
direction/control deploy hack ↓ inside adapter subspace? hack-vs-solve 0.000 yes vampire-vs-werewolves 0.000 yes Haar-random 0.094 no vanilla (no routing) 0.323 n/aSo after seeing the table above (Table 1) I found myself wondering, hang on, why did the vampires vs werewolves sort the hacky samples from the clean? Sure vampires are hackneyed, but then so are werewolves. Vampires are surely cleaner than werewolves, although Twilight (see Meyer ([2011]) or Luminosity fans might disagree. Is this why the steering vector suppressed cheating?
But I joke, this was a silly semantic placebo and it showed that an unrelated semantic direction would separate the samples. In other words it was suspiciously easy.
Random semantic directions are very important baselines. Why? Because sometimes any semantic vector will pick up a salient direction in the model weights, often the one it was most recently, or most, trained on. There is an example here where top-vs-bottom-shelf suppressed eval awareness. I've also seen examples where any semantic vector will pick up helpfulness because it was the last thing trained in the model, so this placebo treatment helps separate that possibility. It paid off here, because it's clearly different than a random direction and raises the question: why does a random semantic direction solve this toy env? The answer: because the toy env is confounded and trivially solvable.
So the direction barely matters here because the toy environment, with on-policy solves and off-policy hacks from the teacher, made the hack trivially separable by any semantic direction, and partly separable by a random hidden space direction. In a realistic setting, where everything is on-policy, it would not be that easy. And this is what I found next.
Investigation: are steering vectors precise classifiers? NoHere I paused and tried to focus in on a more easily answered question. Are steering vectors good enough classifiers? They need to classify clean samples from hacky samples, and this can be tested quickly. A good gradient routing classifier should do pretty well on an F-beta score or have a high AUROC.
I run a single run without any of the previous confounds, and saved the first checkpoint that showed the at least one example of solving and hacking. I also recorded a clean, hacky, and mixed samples from this run. So all the gradients that come from learning these behaviours should be there.
I tried two kinds of pair set: ones I hand-wrote (call these authored), and ones the model wrote itself, generating its own hack and clean completions on the same prompts (self-generated). I also tried many variations such as coding, philosophical, thought based, and so on. In the end I used the best performing, which were the coding pairs.
For each I score the direction as a classifier on the held-out rollouts.
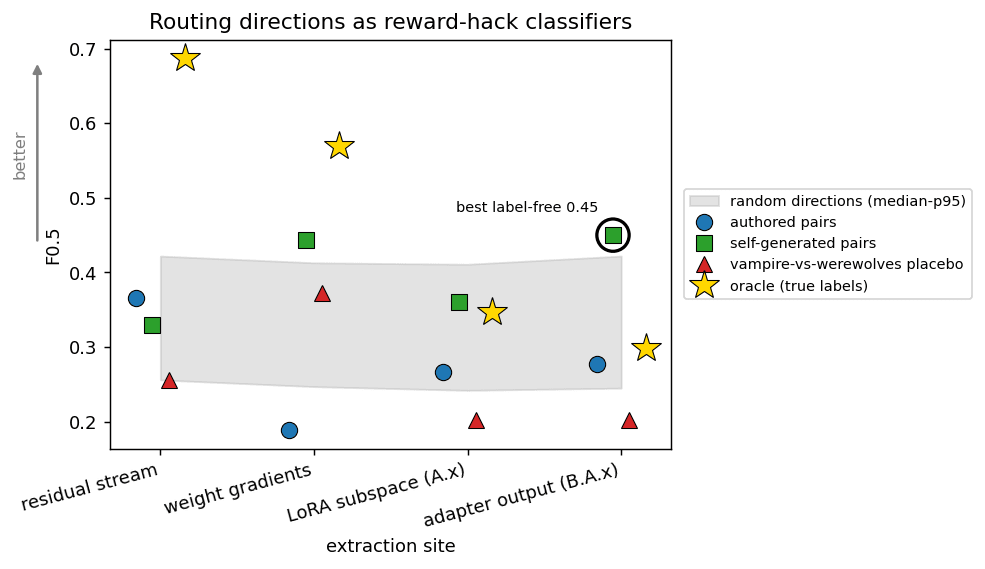
The result is negative (Figure 2, Table 2), steering vectors are poor classifiers in this setting.
Figure 2: No steering vector was a good classifier. The label-free steering vectors (blue, red, green) never get higher than 0.5. The grey band is the spread of random directions. The oracle (gold) is fit on the true labels to show the limitation of the linear steering vector format even if perfect labels are available.
Table 2: Classifier score per extraction site vs steering vector. Every direction is the same per-module t-statistic, differing only in the data it is fit on. Bold is the best classifier at each site: the oracle wins in the residual stream and gradients, but the label-free self-generated direction wins at the two sites closest to the gate (LoRA subspace and adapter output).
extraction site authored self-gen vampire-vs-werewolves (placebo) oracle (true labels) residual stream 0.37 0.33 0.26 0.69 weight gradients 0.19 0.44 0.37 0.57 LoRA subspace (A.x) 0.27 0.36 0.20 0.35 adapter output (B.A.x) 0.28 0.45 0.20 0.30The results, in Table 2, show that no steering vector was a good enough classifier, at least in the setups I tried. Next I confirmed this with full training runs.
Do we even need a router? Can initialisation do the job? Yes, but not as well as with labelsNext I wondered if we even need a router. Since absorption was the key phenomenon here, can we just empower it with contrasting inits? Ideally we would bias one LoRA adapter to learn hacks while the other one learns clean solves. We can use the same synthetic pairs that we used for steering vectors. These runs are in the fixed environment too, on-policy generation with no teacher bootstrap, so the numbers below are not the confounded toy setup from earlier.
To test this I tried a chain of more sophisticated LoRA initialisations, these are shown in Table 3. There, as-trained evaluates the model with the quarantine adapter active, and deploy evaluates it with the quarantine ablated back to its initialisation.
Table 3: Initialisation methods and their deploy results, sorted best (lowest deploy hack) first; each control below removes one ingredient. All five train the identical rank-2r adapter (matched trained parameter count); they differ only in the init and in whether the quarantine half is ablated at deploy. weight aware = seeded from the SVD of the pretrained weights (PiSSA); data aware = also oriented by task-data activations (CorDA); contrastive +/- = the two halves seeded with opposite signs of the hack-minus-clean direction (signed-CorDA, and its sign-reversed control). Only the contrastive (+/-) rows split into a deployed and a quarantine half and ablate the quarantine at deploy, so only they can drop the hack; the rest deploy the full adapter and test whether init alone prevents hacking, which it does not. signed-CorDA rows run 30 steps, the rest 40.
init as-trained hack deploy hack ↓ deploy solve ↑ weight aware data aware contrastive signed-CorDA 0.529 0.195 0.172 y y + signed-CorDA reverse 0.678 0.391 0.103 y y - PiSSA (Meng, Wang and Zhang (2024)) 0.747 0.747 0.138 y n n CorDA (Yang et al. (2024)) 0.770 0.770 0.115 y y n LoRA (Hu et al. (2022)) 0.862 0.862 0.046 n n nThe idea is to bias absorption with the initialisation alone: CorDA (Yang et al., 2024) is a data-aware init, so seeding one half from the signed contrastive direction (the mean hack-minus-clean activation difference) points it at the hack concept and makes it the path of least resistance for the hack gradient, which absorption should then localise there, where deployment can delete it. Over 30 steps the hack saturates the as-trained model (0.759), and ablation then removes ~70% of it (deploy 0.218) at little solve cost (0.161 to 0.149), with no routing gate at all. To my knowledge no prior work shows an init biasing absorption this way. It is a partial success though: the reverse signed-CorDA control shows some causal sign-specific effect, where the deployed model is left both weak (solve 0.15) and still hacking (0.22), so it lessens but does not stop the hack.
ConclusionSteering vectors do not work as classifiers of reward hacking in this environment. However, they can drive initialisations that let gradient routing work without rollout labels. The best result drops held-out hacking from 0.759 to 0.218 (~70%) by absorbing gradients into the hack-initialised quarantine adapter. This is not as good as prior approaches that use labelled examples and get near-perfect suppression. However, there is a place for this self-supervised approach, because strong labels may not be available for unknown reward hacks during frontier training.
If improved, this approach could be used at scale by initialising two adapters for a task from synthetic pairs, then merging only the clean adapter into the model after training is complete.
LimitationsThis is a resource-constrained result, so running larger or more experiments is limited. Please weigh the evidence as given, at the strength you think appropriate.
Despite the constraints, I felt it was valuable to share intriguing results that other researchers might follow up on or adjust their research directions. If you would like to know more, I'd enjoy answering questions in the comments.
The code, including a messy research journal, is at https://github.com/wassname/vGROUT_pub.
Appendix: environment and dev setupI took Ariahw, Engels & Nanda's rl-rewardhacking benchmark (Ariahw, 2025) (it adds a loophole to LeetCode problems) on Qwen3-4B. This is a good environment and probably the smallest reward hacking replication I've seen.
That said it's still a slow process, and I am resource constrained so I modified it to be fast enough to iterate on a single RTX 6000 (the paper used 4xH100, so I am about 4x slower). A step for me is about 32 samples (less than the original). I also updated from GRPO settings to work with lora and small batches: Dr.GRPO-style with a one-sided clip of 0.2, lr 7e-5 (Ariahw's setting), kl_beta 1e-3, and a held-out eval of 32 prompts at T=0.7. Routing operates on two LoRA adapters: a deployed and a quarantine one.
Note: there is now a successor env by the same authors: https://github.com/ariahw/rl-rewardhacking-ext
To reach a hacking checkpoint fast I used one of two shortcuts:
A hacky-teacher bootstrap: inject ~4 hack samples alongside ~28 on-policy student samples each step, then turn the teacher off after 30 steps (~960 samples to learn to hack). It is fast, but it makes the hacks off-policy, which is exactly the confound that broke the routing result here. I would not recommend it for this use case. You can inject an equal amount of solves from the same source, and this helps balance things, but it's still not the sparse environment of normal GRPO so the data balance is different with far less "attempted solves" Save a checkpoint at the first hack and warm-start from it. This seems fine for dev, but the initial learning is baked into the weights and not subject to gradient routing. That said follow up learning happens in a fresh lora so I expect it to be a valid speed-up and did not see any problems so far.I also removed vLLM and SGLang to keep simpler transformers/pytorch code (although around half the speed).