The Paradox of Medical AI Implementation
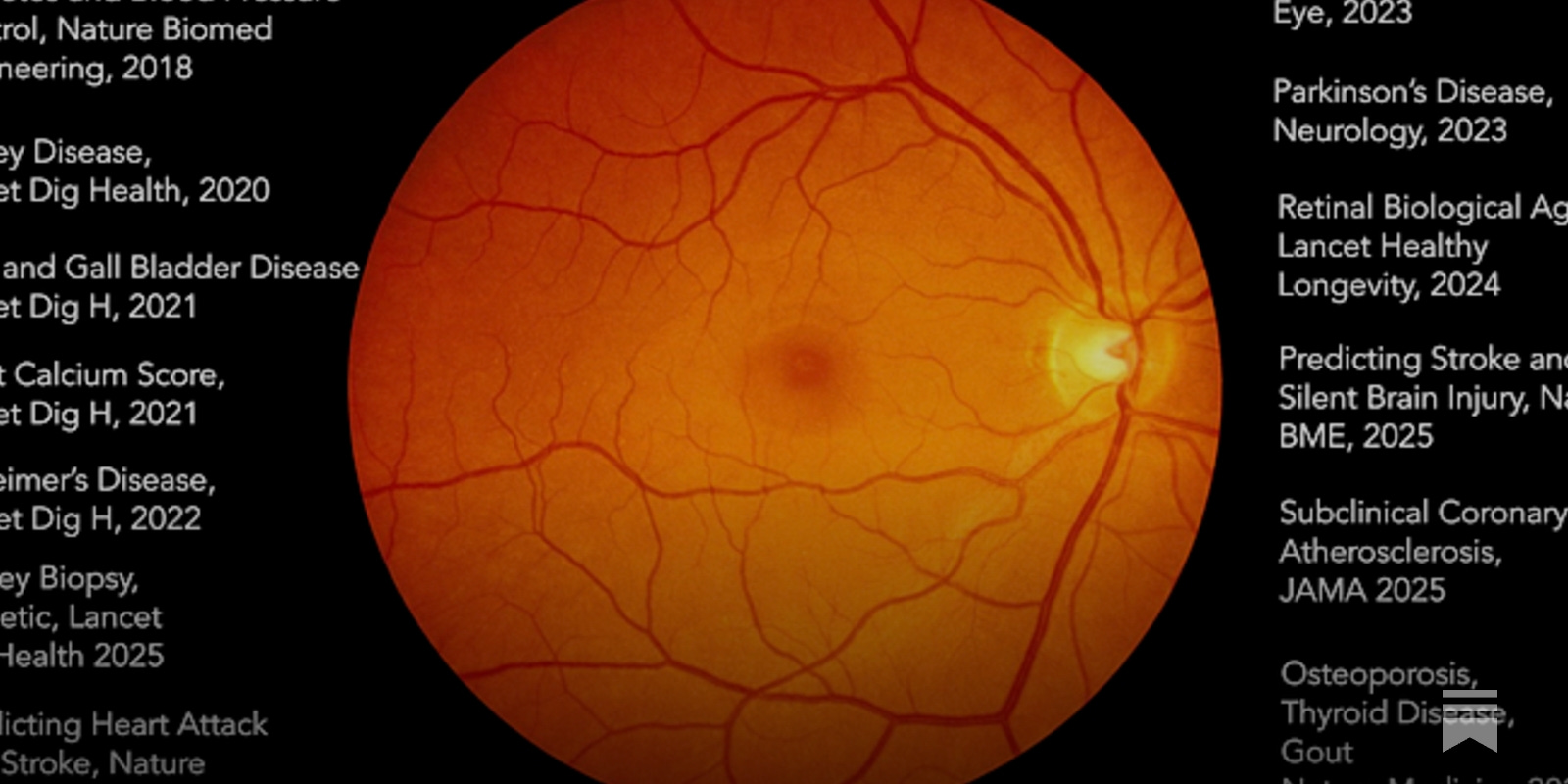
In 2012, the era of deep learning AI got legs with the convolutional neural network (AlexNet) that won the ImageNet challenge. Those images were everyday objects, animals, and scenes, unrelated to health and medicine. Over 7 years ago, I wrote a review in Nature Medicine entitled High-Performance Medicine that summarized the remarkable progress being made for AI interpretation of medical images. Now virtually every type of medical images has undergone extensive assessment with AI, including X-ray, CT, MRI, ultrasound, pathology slides, skin abnormalities, electrocardiograms, endoscopy, and retinal photos. A few weeks ago here in Ground Truths and subsequently in The Lancet , I wrote about 3 AI tools that should be used for every mammogram, based on the largest randomized trial of >100,000 women and 2 recent FDA approvals. There have been 44 randomized trials for colonoscopy that consistently, and in aggregate, demonstrate a substantial advantage of AI-assist for detecting adenomatous polyps compared with gastroenterologists without AI, yet that has not been made part of standard medical practice. In this edition of Ground Truths, I’m going to review the striking and paradoxical contrast between adoption of AI in the deep learning era (DL, pre-transformer model) with contemporary large language models (LLMs), a.k.a. generative AI, an outgrowth of the transformer model (yes, still a form of deep learning), made widely known by the release of ChatGPT in late 2022. Beginning in 2018, we started to take note that the retina fundus photo, or optical coherence tomography (OCT), had far more information embedded in it when “seen” by AI that was not detected by ophthalmologists. This led to the realization that supervised learning of hundreds of thousands to millions of images yielded superhuman vision. Many papers were subsequently published about AI of the retina image that supported it as a gateway to nearly every organ of the body, no less to the risk of Parkinson’s and Alzheimer’s disease many years before any symptoms appeared. These were each derived from single deep learning models probing the ability for the image to predict a certain condition. I gave a TED talk about this in 2023. A few years ago, Pearse Keane and colleagues published the first retina foundation model, a generalized dataset with many downstream tasks, called (RETFound) from 1.6 million images, demonstrating its prediction of heart disease, stroke, glaucoma, and Parkinson’s disease. This week, a new retinal image foundation model (Reti-Pioneer) from over 100,000 photos was published, adding thyroid disease, gout, and osteoporosis to the long list of conditions, beyond previously established Type 2 diabetes, hypertension, and hyperlipidemia, for determination of level of risk (summarized in the Figure). Who would have thought a retina image was this rich?!Most people get an eye exam each year or every other year, which typically includes a photo of the retina. More than half Americans had an eye exam last year, or well over 100 million people. Yet none of the extraordinary progress that has been published for superhuman vision of the retina has been incorporated into routine medical practice! Despite the lack of general use of AI of the retina, at least 4 companies have moved ahead to provide specific results for patients, although sparsely accessible or used in the United States. There’s Optain for cardiovascular risk, Toku Eyes for chronic kidney disease risk and biological age, Mediwhale for cardiovascular and kidney risk, and i-Cognitio Sciences (based in Hong Kong) for Alzheimer’s risk. Although the accuracy of risk of the various conditions is not 100% (= area under the receiver operating characteristic, AUROC of 1.0) this information could be provided for >15 conditions at a nominal cost ($1) or free to all people having an eye exam. But lack of any orchestration of implementing this huge body of work and evidence and issues such as reimbursement have held it back. It’s software that could and should be easily be applied to every retinal image, and someday ought to be part of a “medical selfie” that we could do with automated capture of the fundus using our smartphone and an app readout.Last week, an AI to detect pancreatic cancer was published which detected ductal adenocarcinoma (PDA) up to 3 years ahead of radiologists (median advance interval 475 days) and the detection of occult PDA almost doubled for AI compared with radiologists (73 vs 39%, respectively, Figure below). The multicenter study also had external validation. Yesterday, the FDA gave approval for access to an experimental drug for pancreatic cancer with very promising results. How about access to an AI to detect pancreatic cancer before it would be picked up clinically? In China, AI detection of pancreatic cancer via chest and abdominal CT is becoming routine using their validated AI tool known as PANDA. That is to say, the AI is automatically used for detection even though the scan was ordered for something else. That is essence for what has become known as Opportunistic AI. Some examples are shown in the Figure below.A schematic image I made with the help of ChatGPT Images 2.0There is a long list of missed imaging opportunities that I’ve summarized in the Table. Just a few weeks ago, as I wrote in a Ground Truths, there’s the ability to obtain a thymus health score via AI of a low resolution chest CT. To get critical information about our immune system health which is not clinically obtainable. We’re leaving so much valuable medical information on the table by not incorporating validated means of AI detection to our medical scans. That doesn’t even take into account what is encoded in electrocardiograms, pathology slides, and many other types of medical images that we’re not extracting with AI. In the April issue, the editors in Nature Medicine published this essay calling for evidence. It reminded me of the famous Cuba Gooding line “Show me the money” from the Jerry Maguire movie.As opposed to many randomized trials and prospective assessment with external validation of medical image AI, the evidence with generative AI in medicine is lacking. That has not held back the public or physicians from using AI chatbots and LLMs. For the public, according to multiple surveys, 12% of adults are using an AI chatbot every day, or about 40 million people, and estimates range widely from 32% to 73% for having used a chatbot for health information in the past year. According to a recent survey by the American Medical Association in March 2026 of 1,700 doctors, 72% are using genAI for at least 1 use case, and 35% for direct patient care, that is non-administrative, decision making. The graph below extrapolates that for ~1 million physicians. I made this simple graph with ChatGPT Images 2.0The next graph indicates the projected use by physicians (from the AMA survey) by the end of 2026. You can see expectations are far different than current use! Note the plan for diagnosis assist. For AI based decision support, such as making a diagnosis or optimal management of patients by clinicians, what is the evidence? We don’t really have any real-world data. This week in Science Magazine multiple (6) experiments assessing 2 LLMs (Open AI’s o1 and ChatGPT 4) and physicians for case vignettes supported the potential of improved reasoning and, in a simulation of real world emergency room decisions at 3 touchpoints (graph right below) compared with 2 doctors, there was improved initial triage decisions for 01. Most of the many publications use case studies, simulations, and actors as patients. Hardly representative of the messy world of the practice of medicine.On the patient side, there’s the same deficiency. A limited exception was a small, prospective, single arm study of 100 adult patients (preprint published comparing a model (AIME) vs primary care physicians for differential diagnosis and management plan, which were shown to be on par. A study of ChatGPT Health for helping to triage patients (simulated) to stay home or go to the emergency room did not fare well for the AI, with many blatant triage errors for real emergencies (such as diabetic ketoacidosis or impending respiratory failure (Figure).In a randomized trial of LLMs comparing patients assisted by LLMs for 10 medical scenarios (not real-world), the patients did’t do well (Figure) and the conclusion was “We recommend systematic human user testing to evaluate interactive capabilities before public deployments in healthcare.”There are a couple of exceptions to the lack of real world assessment including a Nature Health paper for use of an LLM in 16 primary care clinics in Kenya and a single center randomized trial in eye care. The latter found a higher diagnostic rate for ophthalmologists using AI (92.2%) compared with those who didn’t (75.4%).In summary, there is very little evidence for LLMs benefiting patients or doctors for health outcomes. That is not to say that generative AI doesn’t help. It offers strong support for administrative work, such as summarizing charts for doctors, or reviewing labs for patients, or providing relevant publications to clinicians and patients, or helping with pre-authorizations for doctors and billing questions for patients. AI chatbots are helping patients prepare for visits, understand their diagnosis and prescriptions. But going back to the Nature Medicine’s call out for evidence, we need it. For LLMs to help doctors make critical diagnoses or treatment decisions, that requires prospective studies, ideally randomized, but at the very least rigorous and large, with independent adjudication of health outcomes. And for the public, how do we know entering all one’s data leads to the correct diagnosis or treatment? This week we learned that the symptom quality reported to an AI was deficient as compared to that presented to a physician. How does the benefit of patient access to genAI compare with potential harm? I’ve reviewed a major paradox whereby AI for medical images, with extensive research dating back more than a decade ago, is not being implemented. Whether it’s a mammogram, a CT scan, a retinal image, or colonoscopy, that have all been extensively studied, their value to improve accuracy and risk assessment in medicine is being missed and essentially disregarded.On the other hand, tens of millions of Americans are using AI chatbots for medical support, as are a substantial proportion of physicians. There are many reasons to use AI here that are easy to support, because they represent an extension of a web/Google search. Just with much more specificity and depth of response, not something that would be subject to regulatory oversight. But when it comes to making a diagnosis or providing a treatment plan there needs to be proof that LLMs are improving accuracy and outcomes. We’ve already seen multiple studies (again not real world) when the AI performed better for various tasks than the doctor with AI, including the new Science paper this week, indicating we don’t even know yet the optimal way of deploying AI (the human-in-the-loop question). As Raj Manrai wrote in his excellent explainer thread, as one of the senior co-authors of the Science paper: “What do our results actually call for? Prospective clinical trials. Health systems investing in infrastructure now. Monitoring frameworks that track not just diagnostic accuracy but safety, efficiency, and cost. The science has reached a point where trials are justified.” We can’t get to high performance medicine, relying on generative AI for key decisions, without that.One sticking point. Unfortunately, by the time peer review papers are published, the models assessed are outdated (such as 01 when GPT5.5 would be current). That can give the AI enthusiasts cover, saying the lack of optimal AI performance was because of a weak and old model. The reality, however, is to prove it. Publish it quickly as a preprint.We’re just a couple of years into the LLM era for medicine. Waymo started in 2009 and it took more than 15 years of rigorous, iterative work to show its true superhuman performance for outcomes with >90% reduction of serious accidents compared with human drivers. Let’s fix this paradox of medical AI implementation. It’s a two-fold and major undertaking. Amping up the use of medical AI where it’s proven and performing the clinical trials required to justify wide-scale adoption where pivotal evidence is lacking.NB This post was written by me, no AI. Two images were made with the help of AI, as indicated. I have no COI related to the content of the post.A big thanks to Ground Truths subscribers (> 205,000) from every US state and 212 countries. Your subscription to these free essays and podcasts makes my work in putting them together worthwhile. If you’re not a subscriber, please join!If you found this interesting PLEASE share it!Paid subscriptions are voluntary and all proceeds from them go to support Scripps Research. They do allow for posting comments and questions, which I do my best to respond to. Please don’t hesitate to post comments and give me feedback. Let me know topics that you would like to see covered.Many thanks to those who have contributed—they have greatly helped fund our summer internship programs for the past two years. It enabled us to accept and support a record number of 51 summer interns coming in 2026! These are high school, college and medical students selected from thousands of applicants. We couldn’t do this expanded program without the funds coming in throughGround Truths. For those of you interested in extending healthspan, my NPR segment this week